Important features¶
LEVEL 1 USER
Platform Independent data model¶
The DATEX II development focussed on the production of a set of reference documents which make a very clear distinction between data (content) and exchange mechanisms. The main part of the work has been focused on the subject of Traffic and Travel Data Models. The technical description provides a very clear distinction between platform independent modelling aspects (PIM) and platform specific modelling aspects (PSM). PIM aspects are described in UML. In each case, a clear distinction between the data modelling (referring to traffic domain) and the data exchange specifications (referring to information and communication technology) were introduced. This approach has been chosen, as it provides several advantages:
- The separation of these aspects provides better understanding of the standard to the users and makes it easier to apply.
- The platform independent aspects can be considered as more stable than the platform (and technology) specific aspects.
- The project has produced explicit models in Unified Modelling Language (UML), which define the contents of DATEX Traffic and Travel publications independent of the exchange mechanism or implementation technology.
Model extensions: A, B, C¶
Level A specification¶
DATEX II v3 delivers a data mode also called “Level A data model” which is the result of studies on data which are shared by a lot of users in Europe. Nevertheless, there will be situations where data concepts required by a specific user are missing in the Data Dictionary, for example because they only make sense in a National context. In this case, these users are expected to provide an extension to the model (named “level B”) that provides the missing concepts. Users are allowed to apply a limited set of well-defined UML mechanisms for these level B extensions, which then still maintain technical interoperability with standard DATEX II systems. This means that standard (i.e. level A) compliant systems will still be able to process publications generated from an extended model, of course without being able to process the extension content. Specialised clients can process the full content – including the extension – but of course can also process standard (i.e. level A) publications. The main principle of level B is thus that users find the level A model appropriate for a large part of their publications. This may not be the case if entirely new concepts outside the scope of the level A model are introduced. In this scenario, DATEX II users are still expected to apply the modelling rules and the UML profile described in the standards, which will provide them with a basic level of interoperability. These models are denoted as “level C”. Implementations that provide publications according to level C extensions cannot expect to be interoperable with standard level A systems.
The extended model - “Level B” Extension mechanisms¶
Although the “A” model is rich, over time there will always be cases where new applications, both at national and international level, will want to add additional concepts and attributes to the existing models. To cater for this future proofing aspect of the modelling it is desirable to have a formal mechanism by which the “A” model can be extended. For these new applications requiring extensions to the “A” model, the concept of Level B compliance has been created. This will allow development of specific models that will enrich the “A” model with additional, application specific information. These models/applications will remain interoperable with “A” model compliant suppliers/consumers: they can exchange objects structured according to these enriched models. Suppliers/consumers that want to make full use of the information defined by these extensions to the “A” model will need additional software or metadata driven software to handle the additional application specific information. A registration process for level B model extensions is available on the DATEX II website (www.datex2.eu), under the authority of the DATEX TMG. Once an extension achieves a major degree of consensus it would become a candidate to be absorbed into a new version of the formal DATEX II level A.
Level C Extensions¶
Using the DATEX II concepts within different contents – “Level C” Users and Models - after consideration of Level A and Level B compliance rules some users within the ITS domain may still find that there is no way that their specific data models can be accommodated. They are just too different from the Level A model or else cover completely different contents. That’s why the concept of “level C” has been created. Level C implementations are to be considered as not compliant with the DATEX II Level A/B content models. However, they are to be compliant in all other aspects of the DATEX II specifications. Obviously these Level C compliant systems would not be interoperable with Level A compliant systems, but at least they would use common modelling rules and common exchange protocols. This would allow opportunities for the exchange of ideas and modelled concepts which may in the future lead to common model elements facilitated via some sort of model registration process. It will also permit many helpful software tools to be used with Level C compliant contents.
Note
For more in depth information on extensions go to the extension guide.
Data dictionary¶
The DATEX standard provide definitions which are readable by traffic engineers and IT experts alike. As the definitions for the data content in DATEX II are only stored within the UML model, which are not simply accessible for reading by non-IT professionals, a readable data dictionary is available via a software tool which automatically extracts the definitions from the UML model. An excel file with the dictionary can be found here.
XML schemas¶
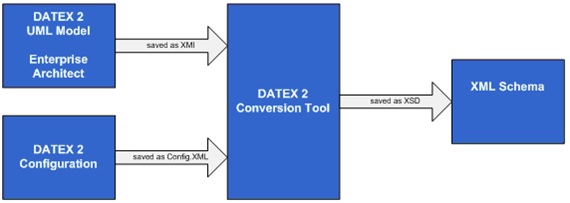
Today there is a growing market and use of XML for information exchange. A fundamental part of this approach are the XML Schemas. Based on a data model and a data dictionary, the XML Schema are designed to fit a certain area of applications. The schemas are the tool to understand the content of the exchanged data. A conversion tool has been developed to convert the UML DATEX II data model into a set of XML schemas. The UML model is first exported from the UML modelling tool into an XMI file which the conversion tool then converts to a set of XML schemas. The XML schemas are used for development of real exchanges, by software developers . XMI (XML Metadata Interchange) is an OMG standard for exchanging metadata information via XML. It can be used for any metadata whose metamodel can be expressed in MOF (Meta-Object Facility). The most common use of XMI is as an interchange format for UML models, although it can also be used for serialization of models of other languages (metamodels). The following figure shows the workflow for an automated conversion process.
Exchange mechanisms¶
Generally speaking, DATEX II offers a push and a pull mode for information exchange. The push mode (as in DATEX) allows the supplier to send information to the client while the pull mode allows the client to request the download of information from the supplier’s systems. In detail, DATEX II provides the exchange mechanisms as described below. At a high description level document for details), without considering the notion of technical platforms, data exchange between a supplier and its client(s) can be accomplished by three main operating modes:
- Operating Mode 1 - Publisher Push on occurrence
- data delivery initiated by the publisher every time data is changed
- Operating Mode 2 - Publisher Push periodic
- data delivery initiated by the publisher on a cyclic time basis
- Operating Mode 3 - Client Pull
- data delivery initiated by the Client, where data is returned as a response.
Each Operating Mode can be both on- and offline. For the “Client Pull” operating mode, two implementation profiles have been defined for implementing this operating mode over the Internet: by direct use of the HTTP/1.1 protocol or via Web Services over HTTP. For the “Supplier Push” operating modes, one platform has been defined using Web Services over HTTP. The common corresponding document, describing all operating modes and both profiles for Client Pull as well as their interoperability, is [Exchange PSM]. PSM exchange documents have been designed to be independent from the exchanged content (the payload). These documents can be studied without knowing the details of the UML DATEX II data model.
DATEX II Profile¶
DATEX II allows exchange for several kinds of data via several Exchange Specific Platforms. Not all of those PSM’s have necessarily to be implemented in every DATEX II system and not all data content need be implemented. Thus DATEX II allows the implementation of profiles. “Profiling” aims to define a customised subset of options offered by a standard for a particular need.
The profiling guide section of the portal gives an in depth description of the profiling methodology.
What is a Profile?¶
A DATEX II system is composed of different publications which can be delivered with different Exchange PSM’s. Each DATEX II system builder chooses to implement the subset of couple publications - Functional Exchange Profile + Exchange Pattern(FEP+EP) implemented by an Exchange PSM based on his needs. This subset is called a « DATEX II profile ».
The need is to have profiles and options that allow DATEX II users to customize their implementations in order to provide more or less functionalities/facilities as necessary and not to be forced into implementing all the features. DATEX II allows every user to define a profile according to his own requirements whilst keeping interoperability on common parts (publications, operating modes) with other users.
What must the stakeholder choose?¶
Because different needs for different use cases of DATEX II may lead to the definition of different profiles, this step will require close stakeholders’ involvement to elicit their requirements. Moreover, profiling will require assessment of the cost/benefit trade-off, in particular of:
- standard features/services;
- implementation platforms; and
- level of service that must be achieved.
Stakeholders need to provide their own perspective which will influence the main choices to be made concerning:
- the list of publications to be exchanged,
- the Exchange Requirement to be fulfilled and Exchange Features to be implemented,
- and sometimes also specific technology PSM’s, options.
Evolution from V2.0 to V3.0¶
The main conceptual modifications from DATEX II v2.0 to DATEX II v3.0 are:
- modularisation,
- definite split between data and exchange,
- ability to include external data structures,
- proper exchange PIM and PSM’s.
The main modifications about content are:
- addition of
- missing information elements
- approved v2.x extensions
- flexibility when using linear referencing systems;
- improvement of
- extensibility
- information structures
- consistency of accidents and vehicle obstructions;
- introduction of
- a new location referencing system based on ISO/PRF TS 21219-22 “OpenLR™”;
- a new location referencing g system for linear features based on GML LineString;
- features to deal with 3D coordinates and accuracy assessment;
- enabling the mark up of Safety Related traffic information according to Commission Delegated Regulation (EU) No 886/2013;
- remodelling of
- the cause of traffic situations, better fitting the operational use;
- the “PredefinedLocationsPublication”
- removal of:
- the TrafficView,
Note
More details can be found in the release notes.